
Day 1 - Coroutine or Coroutine Function
I’m going to Review 30 python pull requests in 30 days (In these series, python=cpython).
Why?
Python need reviewers
developer guide points out:
One of the bottlenecks in the Python development process is the lack of code reviews. If you browse the bug tracker, you will see that numerous issues have a fix, but cannot be merged into the main source code repository, because no one has reviewed the proposed solution.
Python only have 90 reviewers, I used to think large companies like Google and Apple who are using python would donate a lot of money to The Python Software Foundation. However, the reality is python maintainers didn’t get pay for their work. I need money just like others, but I also like to work with people who enthusiasm with open source projects and do not work for money. If you also want to work for an open source friendly company, try Open Source Jobs.
learn by contributing and give back to the community
About two years ago, I asked a question about Scrapy on Stackoverflow. Dimitrios, the author of Learn Scrapy gave a beatuful answer. After answered my last question, He told me:
Just subscribe to Stack Overflow to get some questions and you may be able to answer a few of them here and there… it’s fun! :)
So I started a challenge named Answer 30 question in 30 days. After I finished the challenge, I gained some reputations in StackOverflow, plenty of thank you and most importantly, I learned quite a lot by answering these questions which I didn’t expect.
If you ask someone how to learn programming, they would recommend you some books or MOOCs which are great. However, learn by contributing is also a great way to improve programming skills. Some people never answer a question on StackOverflow because they think they are not capable enough. This also happens in people who afraid to get involved in an open source project, they think the project is written by God, they can’t do anything to improve it. But the truth is, we can, and I will show you how to achieve it in this article. BTW, some open source projects are so large that even the maintainers do not understand each part of it.
I use python for more than three years. Since I quit my job last month, I do have some time to improve myself and give back to the community, we are not owing each other :D.
Call for contributors
Python has millions of users but less than 700 contributors. In these series, I will show you how to review a PR step and step (feel free to give me some advises if you have a better workflow). I hope this would let people find some confidence to contribute to a large open source project. BTW, I didn’t study computer science at my college. So if I can do this, most people can do this.
Practice my writing skills
These series are not written by a 12 years old child, I’m not a native speaker but I am doing my best to write some great articles.
Step 1: commit messages and files changed
I started on September 19, 2018, the newest pull request is at this time is pull_9408.
commit messages
Every PR should have an issue number in its commit messages, like bpo-34732: …. But this PR doesn’t have one so I can’t find any discussions about it.
files changed
It looks like a piece of cake because it just adds two characters in the document.
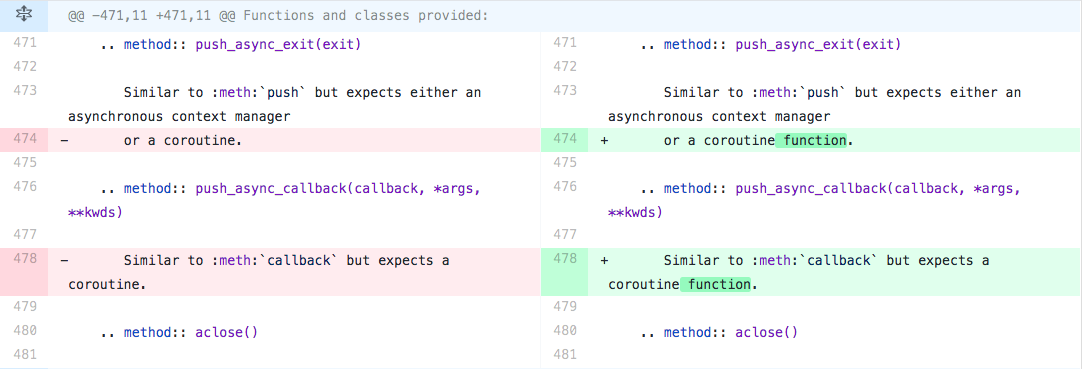
But the devil is in the detail. The files changed are about coroutine, one of the hardest topics in python. It’s so complicated that this repo even has a label call expert-asyncio. So it’s not as easy as it looks like.
Step 2: dive into the source code
Search context
Relax, The first thing we have to do is find out what type of parameters push_async_exit accept. I searched push_async_exit in python repo and found:
def push_async_exit(self, exit):
"""Registers a coroutine function with the standard __aexit__ method
signature.
Can suppress exceptions the same way __aexit__ method can.
Also accepts any object with an __aexit__ method (registering a call
to the method instead of the object itself).
"""
_cb_type = type(exit)
try:
exit_method = _cb_type.__aexit__
except AttributeError:
# Not an async context manager, so assume it's a coroutine function
self._push_exit_callback(exit, False)
else:
self._push_async_cm_exit(exit, exit_method)
return exit # Allow use as a decorator
the comments say:
Registers a coroutine function with the standard __aexit__ method signature.
It looks like this function accepts a coroutine function as a parameter. We should accept the PR, right? Here is the funniest part, just like when you are trying to solve a Leetcode problem, you have to find out all the edge case. Is it possible that the push_async_exit should accept a coroutine, the PR and the comments are wrong at the same time? Let’s use git blame to figure it out:
>>> git blame cpython/Lib/contextlib.py
1aa094f7403 (Ilya Kulakov 2018-01-25 12:51:18 -0800 556) def push_async_exit(self, exit):
1aa094f7403 (Ilya Kulakov 2018-01-25 12:51:18 -0800 557) """Registers a coroutine function with the standard __aexit__ method
1aa094f7403 (Ilya Kulakov 2018-01-25 12:51:18 -0800 558) signature.
1aa094f7403 (Ilya Kulakov 2018-01-25 12:51:18 -0800 559)
1aa094f7403 (Ilya Kulakov 2018-01-25 12:51:18 -0800 560) Can suppress exceptions the same way __aexit__ method can.
1aa094f7403 (Ilya Kulakov 2018-01-25 12:51:18 -0800 561) Also accepts any object with an __aexit__ method (registering a call
1aa094f7403 (Ilya Kulakov 2018-01-25 12:51:18 -0800 562) to the method instead of the object itself).
1aa094f7403 (Ilya Kulakov 2018-01-25 12:51:18 -0800 563) """
1aa094f7403 (Ilya Kulakov 2018-01-25 12:51:18 -0800 565) try:
1aa094f7403 (Ilya Kulakov 2018-01-25 12:51:18 -0800 566) exit_method = _cb_type.__aexit__
1aa094f7403 (Ilya Kulakov 2018-01-25 12:51:18 -0800 567) except AttributeError:
They shared the same commit id so it is likely that the comment are correct. I’m not sure, so let’s dive into the code.
Find call stack
I followed the function call stack
# Call stack
_exit_callbacks.append((is_sync, coroutine)) # stack top
_push_exit_callback(coroutine)
push_async_exit(coroutine) # stack bottom
# How AsyncExitStack use _exit_callbacks
while self._exit_callbacks:
is_sync, cb = self._exit_callbacks.pop()
try:
if is_sync:
# Here is the trick
cb_suppress = cb(*exc_details)
else:
cb_suppress = await cb(*exc_details)
The code shows that cb(what we passed) is a callable object. So The next thing we have to do is find out whether coroutine function or coroutine is a callable object.
Step 3: understand coroutine
What is coroutine
One of the lessons I learned from the python community is You should not submit or review the code you don’t understand, even it looks work. So I have to make sure I understand the difference between coroutine and coroutine function.
From the docs and coroutine object
coroutine
- Coroutines is a more generalized form of subroutines. Subroutines are entered at one point and exited at another point. Coroutines can be entered, exited, and resumed at many different points. They can be implemented with the async def statement. See also PEP 492.
coroutine function
- A function which returns a coroutine object. A coroutine function may be defined with the async def statement and may contain await, async for, and async with keywords. These were introduced by PEP 492.
Coroutine objects are what functions declared with an async keyword return.
And finally, why confusion happens
Note that in this documentation the term “coroutine” can be used for two closely related concepts:
a coroutine function: an async def function;
a coroutine object: object returned by calling a coroutine function.
(At this time, I found the PR had been merged by the author of PEP 492)
Step 4: Prove speculation
Now I see, coroutine function is a function return a coroutine object, coroutine object is an abstract object return by coroutine function. I wrote an example to prove my speculation.
import asyncio
# coroutine function
async def foo():
return 42
async def main():
# print <class 'function'>
print(type(foo))
# print <class 'coroutine'>
print(type(foo()))
# TypeError: 'coroutine' object is not callable
print(type(foo()()))
asyncio.run(main())
We make it! coroutine object is not callable. The coroutine in the document is ambiguous and we should use a coroutine function alternative, and yes, we should accept the PR. But wait, now you understand coroutine right? No, I didn’t, I still don’t understand how it works, but I know more about it now.
Conclusion
I’m not familiar with coroutine, I spend 4 hours to review this tiny PR when an expert only need 1 minute. Before I figured it out the PR already been merged, Does it worth? My answer is yes, of course.
I found other documents to improve
Since we accept the PR, we can improve other documents about coroutine, coroutine function and coroutine object. For instance, I found some of them after search a coroutine in GitHub, this also happens at PEP492
The following new syntax is used to declare a native coroutine:
async def read_data(db):
pass
I can improve the document after this useless review. and I created an issue
I know more about coroutine now
Concurrency is a hard topic in python and I want to be an expert in it. I’m kinda moving forward, right?
See you tomorrow and feel free to leave any suggestions.